Microservice-ish architecture with .NET Core and Azure Service Bus
This is a blog post was originally posted on the Novanet blog some time ago. It's based on one of the first project were I contributed to successfully implementing a microservice architecture. It's a bit dated, but still some valid points.
Microservices, events and serverless are all trending topics when it comes to software architecture. This blog post gives a practical approach to becoming trendy. I'll show you how I've set up my microservices, how you can generate events from changes in your application, and how to combine services on-premises with services in the cloud. With Azure Service Bus binding everything together.
I've recently been working on several similar projects. Developing integrations for the employee life cycle, from the employees are recruited to they're offboarded. The life cycle or process is mostly the same, but the applications involved differ from project to project. There is usually an application for recruitment, one for HR, another one for pay roll, maybe one for competence and something for identity.
The applications offer integrations ranging from extensive REST APIs to receiving a ZIP-file download link on e-mail. I wanted to go for an event-based microservice architecture but given all these different kinds of integrations I needed to do some adjustments. This blog post covers some of the common architectural choices made and the reasoning behind them. In addition to some useful implementation details.
Microservices
I decided to create each microservice as a ASP.NET MVC site. Wait, what?! Well, I decided to create a small UI for each microservice. The UIs would contain links to Swagger and the Hangfire dashboard, and in some cases an overview some of the data. After a while the UI was used by developers and operations, and we even added some functionality to it.
A solution could look something like this:
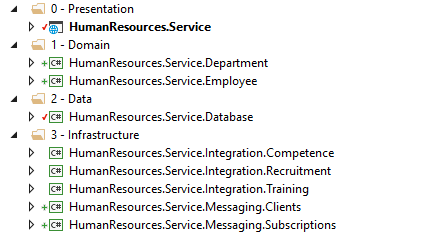
The HumanResources.Service would be the ASP.NET MVC project, containing both API Controllers and the Views (Razor-pages). The Domain projects contains domain specific logic. Data contains the data access layer. While the infrastructure projects have integrations to other microservices, a message bus and other infrastructure stuff.
Integrations
When starting projects like this I usually start by looking at each application and what kind of integration they offer. Getting the right data from a 3rd party application usually takes time. You'll need documentation (if any), access information, a test environment etc. Sometimes the integration doesn’t provide the data needed, and the 3rd party will have to develop a new service or file export. So, asking for the things you don't control early is a good idea.
When having enough information to start an integration, I create a facade service. The reason for this is to abstract the underlying application/integration from the rest of the infrastructure. If the customer ever decides to switch to a new application, for let's say pay roll, then all they need to do is rewrite the internal implementation of the facade service. The interface (API) and published events remains the same (hopefully). So, no changes need to be made to the rest of the system. By creating a facade service, we ensure that there is only one place to get data from the underlying application and create nice REST APIs for the rest of the developers that don't have to know anything about the complexity of the underlying integration.
Recurring jobs
I wanted to publish events based on changes in the data of each application. None of the applications in any of the projects offered a way to push changes (with Webhooks or similar) to the integration. So, I decided to use Hangfire to pull data (from API, XML files etc.) on a recurring schedule (like every ten minutes). If you're not familiar with Hangfire, you should check it out. It offers an easy way to do background processing in .NET projects.
In the Hangfire job I would read the data from the source (API, file etc.), then store it in a database. I could then check if the element is new or existing and send the corresponding message to a message bus (I'll cover messaging later). In some cases, I would have to check field-by-field if there really was changes to the element. If you have the possibility to query the data by "changed date" or similar, that helps restricting the amount of data you must check, and you can retrieve only the changes since last time the Hangfire job ran.
By regularly getting the latest data and storing it in a database, the facade service can respond to the rest of the system even if the data source (3rd party application/API) is down. Very microservice-ish.
Messaging
So, I wanted to communicate between microservices using a message bus. Creating less dependencies between services and a more robust architecture (with queuing and guaranteed delivery). So, for messaging I went with Azure Service Bus. Having used on-prem message busses (like RabbitMQ) previously, I wanted to check out a message bus in the cloud.
I found the implementation fairly simple, making use of the nuget packages from Microsoft. The trick was to make use of the IHostedService interface in .NET Core to listen to messages from the message bus as a background task. You register the message handler in the StartAsync-method, then handle the message in the ProcessMessageAsync-method. To make use of the .NET Core dependency injection you need to create your own scope within the ProcessMessageAsync-method and get the required services yourself. Something like this (some implementation details left out for simplicity):
public async Task StartAsync(CancellationToken cancellationToken)
{
_subscriptionClient.RegisterMessageHandler(ProcessMessageAsync, GetMessageHandlerOptions());
}
protected override async Task ProcessMessageAsync(Message message, CancellationToken token)
{
using (var scope = _serviceProvider.CreateScope()) //IServiceProvider injected in the constructor
{
var someChangeHandler = scope.ServiceProvider.GetRequiredService<ISomeChangeHandler>();
await someChangeHandler.Handle(message);
}
}
If you want an even simpler implementation you could use Fishbus, a tiny, tiny library for receiving azure service bus messages. Created by some colleagues from Novanet.
Sending messages is pretty straight forward using the ITopicClient interface.
Cloud ready
The customers I worked at implementing this solution wasn't ready to go all cloud. They had some core application that needed to run on-premises. But by choosing Azure Service Bus for messaging I feel the solution is at least "cloud ready". I can send events from an internal server to Azure Service Bus, then handle the event in the cloud. Same the other way, I can send an event from a cloud-hosted service and handle it in an on-prem service. This makes it possible to gradually move things into the cloud.
To access Azure Service Bus from internal servers, you'll have to open some ports and whitelist some IP-addresses. This is described in this article from Microsoft.
Payload
So, what to put in the message payload? I feel this is often a discussion when dealing with message busses. For this solution I decided to put just the identifier of the object that had been changed in the payload. When handling the message, I call the microservice who was the source of the message to retrieve the full object. The reason for this is that you can't guarantee the order in which the messages will arrive. So, you might get an "ElementUpdated"-message and an "ElementDeleted" message in the wrong order, which might cause you problems. By retrieving the latest version of the object, you avoid having to handle order issues. The downside is that you create a dependency between the services, and the subscriber will have to know where to get the object (endpoint URL). This dependency could have been avoided if I had sent the full object in the payload.
Monitoring
After a while there was several microservices, hosted in different places, which all needed monitoring. I wanted all the microservices to log to the same place and decided to use Azure Application Insights. Just adding Application Insights to a project gives you a lot of monitoring out-of-the-box. But I also wanted the services to log to a single instance of Application Insights and to log some of the stuff going on with Hangfire and Azure Service Bus.
When all the microservices are going to log to the same instance of Application Insights, we must be able to separate the different microservices within Application Insights. This can be done by using the Cloud Role Name. When all the microservices has their own Cloud Role Name, you can filter on the name in Application Insights to create monitoring. For instance, a diagram showing log events for only one of the microservices. You can set the Cloud Role Name with a Telemetry Initializer, like this:
internal class ProjectTelemetryInitializer : ITelemetryInitializer
{
private readonly string _cloudRoleName;
public ProjectTelemetryInitializer(string cloudRoleName)
{
_cloudRoleName = cloudRoleName;
}
public void Initialize(ITelemetry telemetry)
{
telemetry.Context.Cloud.RoleName = _cloudRoleName;
}
}
Having set up Application Insights, I wanted to do some custom logging. This can be done by using the TrackEvent method on TelemetryClient (from the Microsoft.ApplicationInsights package). Another option is to use Serilog and their Applications Insights sink. Then all your logging will go to Application Insights.
To start off with I decided to log:
- When publishing an event
- When starting a Hangfire job
- When completing a Hangfire job
This gives us the possibility to create some nice charts in the Application Insights dashboard. Like these showing new employees or completed courses based on events:
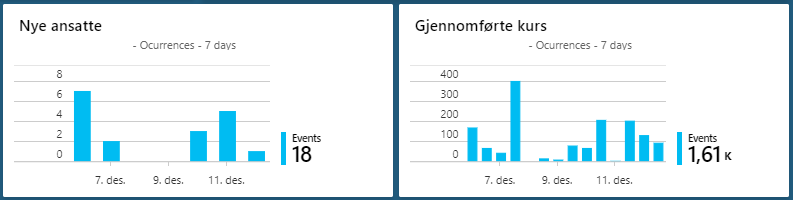
And this one, showing one line for jobs started and one for jobs completed. If they diverge, there is a problem. So, I guess I have some work to do.
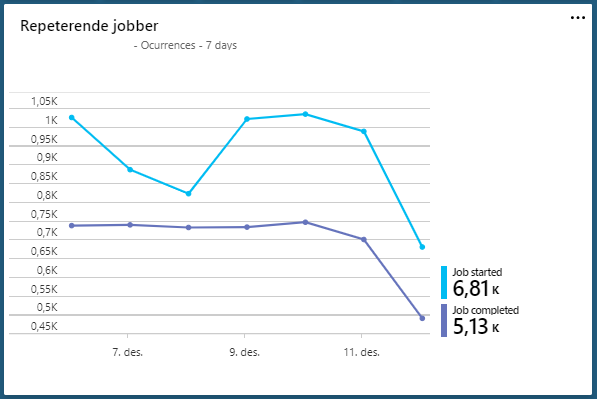
In addition, Application Insights logs all exceptions/failures. With all this log data we have a lot of possibilities for monitoring. An alternative to Azure Application Insights would be to use the Elastic-stack. Logging to Elasticsearch and showing the charts with Kibana. ELK can run both in the cloud or on premises. But that's a different topic.
Next steps
All the above is now in production and running with no major problems. But there is still a lot of work I want to do.
An obvious task is to move more internal stuff to the cloud. The customers are considering moving some of their applications to the cloud. So, the microservices that now run on-premises can be moved to the cloud.
We will also consider moving away from Hangfire and use Azure Functions instead. Azure Functions can run on a timed trigger like Hangfire and do the same tasks. At least the ones that doesn’t rely on on-prem stuff. Maybe we should consider doing hybrid connection, to make the on-prem stuff available in Azure.
We could also use Azure Function for all the message handlers. Azure Functions has an Azure Service Bus trigger, so all the message handlers can run separately without being part of a service.
And of course, more monitoring. The dashboard needs more charts. This will help handing the solution over to operations. Maybe start using the Serilog sink mentioned above, and log everything with Serilog.
Comments
The solutions are working fine, but there is always room for improvement. So, all comments or questions are welcomed!